Statistical analysis
Xiaotao Shen (https://www.shenxt.info/)
Created on 2021-12-04 and updated on 2022-03-09
statistical_analysis.RmdData preparation
Now the positive mode and negative mode have been annotated respectively. We need to merge positive and negative mode data.
Remove the features without annotations
Positive mode
object_pos2 <-
object_pos2 %>%
activate_mass_dataset(what = "annotation_table") %>%
filter(!is.na(Level)) %>%
filter(Level == 1 | Level == 2)
object_pos2
#> --------------------
#> massdataset version: 0.99.1
#> --------------------
#> 1.expression_data:[ 206 x 259 data.frame]
#> 2.sample_info:[ 259 x 6 data.frame]
#> 3.variable_info:[ 206 x 6 data.frame]
#> 4.sample_info_note:[ 6 x 2 data.frame]
#> 5.variable_info_note:[ 6 x 2 data.frame]
#> 6.ms2_data:[ 1042 variables x 951 MS2 spectra]
#> --------------------
#> Processing information (extract_process_info())
#> create_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset create_mass_dataset() 2022-01-16 16:19:04
#> process_data ----------
#> Package Function.used Time
#> 1 massprocesser process_data 2022-01-16 16:18:43
#> mutate ----------
#> Package Function.used Time
#> 1 massdataset mutate() 2022-01-16 23:48:08
#> mutate_variable_na_freq ----------
#> Package Function.used Time
#> 1 massdataset mutate_variable_na_freq() 2022-01-18 09:11:43
#> 2 massdataset mutate_variable_na_freq() 2022-01-18 09:11:43
#> 3 massdataset mutate_variable_na_freq() 2022-01-18 09:11:43
#> filter ----------
#> Package Function.used Time
#> 1 massdataset filter() 2022-01-18 09:11:44
#> 2 massdataset filter() 2022-03-07 17:27:45
#> 3 massdataset filter() 2022-03-07 17:27:45
#> impute_mv ----------
#> Package Function.used Time
#> 1 masscleaner impute_mv() 2022-01-18 09:38:02
#> normalize_data ----------
#> Package Function.used Time
#> 1 masscleaner normalize_data() 2022-01-18 09:38:07
#> integrate_data ----------
#> Package Function.used Time
#> 1 masscleaner integrate_data() 2022-01-18 09:38:08
#> update_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset update_mass_dataset() 2022-01-19 21:53:01
#> mutate_ms2 ----------
#> Package Function.used Time
#> 1 massdataset mutate_ms2() 2022-01-19 21:53:36
#> annotate_metabolites_mass_dataset ----------
#> Package Function.used Time
#> 1 metid annotate_metabolites_mass_dataset() 2022-02-22 21:16:23
#> 2 metid annotate_metabolites_mass_dataset() 2022-02-22 21:30:10
#> 3 metid annotate_metabolites_mass_dataset() 2022-02-22 21:47:59Negative mode
object_neg2 <-
object_neg2 %>%
activate_mass_dataset(what = "annotation_table") %>%
filter(!is.na(Level)) %>%
filter(Level == 1 | Level == 2)
object_neg2
#> --------------------
#> massdataset version: 0.99.1
#> --------------------
#> 1.expression_data:[ 165 x 259 data.frame]
#> 2.sample_info:[ 259 x 6 data.frame]
#> 3.variable_info:[ 165 x 6 data.frame]
#> 4.sample_info_note:[ 6 x 2 data.frame]
#> 5.variable_info_note:[ 6 x 2 data.frame]
#> 6.ms2_data:[ 1092 variables x 988 MS2 spectra]
#> --------------------
#> Processing information (extract_process_info())
#> create_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset create_mass_dataset() 2022-01-16 16:20:02
#> process_data ----------
#> Package Function.used Time
#> 1 massprocesser process_data 2022-01-16 16:19:48
#> mutate ----------
#> Package Function.used Time
#> 1 massdataset mutate() 2022-01-16 23:48:08
#> mutate_variable_na_freq ----------
#> Package Function.used Time
#> 1 massdataset mutate_variable_na_freq() 2022-01-18 09:11:47
#> 2 massdataset mutate_variable_na_freq() 2022-01-18 09:11:47
#> 3 massdataset mutate_variable_na_freq() 2022-01-18 09:11:47
#> filter ----------
#> Package Function.used Time
#> 1 massdataset filter() 2022-01-18 09:11:47
#> 2 massdataset filter() 2022-03-07 17:27:46
#> 3 massdataset filter() 2022-03-07 17:27:46
#> impute_mv ----------
#> Package Function.used Time
#> 1 masscleaner impute_mv() 2022-01-18 09:38:06
#> normalize_data ----------
#> Package Function.used Time
#> 1 masscleaner normalize_data() 2022-01-18 09:50:47
#> integrate_data ----------
#> Package Function.used Time
#> 1 masscleaner integrate_data() 2022-01-18 09:50:47
#> update_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset update_mass_dataset() 2022-01-19 21:53:37
#> mutate_ms2 ----------
#> Package Function.used Time
#> 1 massdataset mutate_ms2() 2022-01-19 21:54:06
#> annotate_metabolites_mass_dataset ----------
#> Package Function.used Time
#> 1 metid annotate_metabolites_mass_dataset() 2022-02-22 21:50:29
#> 2 metid annotate_metabolites_mass_dataset() 2022-02-22 22:08:10
#> 3 metid annotate_metabolites_mass_dataset() 2022-02-22 22:26:33Merge data
We need to merge positive and negative mode data as one mass_dataset class.
head(colnames(object_pos2))
#> [1] "sample_06" "sample_103" "sample_11" "sample_112" "sample_117"
#> [6] "sample_12"
head(colnames(object_neg2))
#> [1] "sample_06" "sample_103" "sample_11" "sample_112" "sample_117"
#> [6] "sample_12"
object <-
merge_mass_dataset(x = object_pos2,
y = object_neg2,
sample_direction = "inner",
variable_direction = "full",
sample_by = "sample_id",
variable_by = c("variable_id", "mz", "rt"))
object
#> --------------------
#> massdataset version: 0.99.14
#> --------------------
#> 1.expression_data:[ 371 x 259 data.frame]
#> 2.sample_info:[ 259 x 11 data.frame]
#> 3.variable_info:[ 371 x 9 data.frame]
#> 4.sample_info_note:[ 11 x 2 data.frame]
#> 5.variable_info_note:[ 9 x 2 data.frame]
#> 6.ms2_data:[ 2084 variables x 1902 MS2 spectra]
#> --------------------
#> Processing information (extract_process_info())
#> create_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset create_mass_dataset() 2022-01-16 16:19:04
#> process_data ----------
#> Package Function.used Time
#> 1 massprocesser process_data 2022-01-16 16:18:43
#> mutate ----------
#> Package Function.used Time
#> 1 massdataset mutate() 2022-01-16 23:48:08
#> mutate_variable_na_freq ----------
#> Package Function.used Time
#> 1 massdataset mutate_variable_na_freq() 2022-01-18 09:11:43
#> 2 massdataset mutate_variable_na_freq() 2022-01-18 09:11:43
#> 3 massdataset mutate_variable_na_freq() 2022-01-18 09:11:43
#> filter ----------
#> Package Function.used Time
#> 1 massdataset filter() 2022-01-18 09:11:44
#> 2 massdataset filter() 2022-03-07 17:27:45
#> 3 massdataset filter() 2022-03-07 17:27:45
#> impute_mv ----------
#> Package Function.used Time
#> 1 masscleaner impute_mv() 2022-01-18 09:38:02
#> normalize_data ----------
#> Package Function.used Time
#> 1 masscleaner normalize_data() 2022-01-18 09:38:07
#> integrate_data ----------
#> Package Function.used Time
#> 1 masscleaner integrate_data() 2022-01-18 09:38:08
#> update_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset update_mass_dataset() 2022-01-19 21:53:01
#> mutate_ms2 ----------
#> Package Function.used Time
#> 1 massdataset mutate_ms2() 2022-01-19 21:53:36
#> annotate_metabolites_mass_dataset ----------
#> Package Function.used Time
#> 1 metid annotate_metabolites_mass_dataset() 2022-02-22 21:16:23
#> 2 metid annotate_metabolites_mass_dataset() 2022-02-22 21:30:10
#> 3 metid annotate_metabolites_mass_dataset() 2022-02-22 21:47:59
#> create_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset create_mass_dataset() 2022-01-16 16:20:02
#> process_data ----------
#> Package Function.used Time
#> 1 massprocesser process_data 2022-01-16 16:19:48
#> mutate ----------
#> Package Function.used Time
#> 1 massdataset mutate() 2022-01-16 23:48:08
#> mutate_variable_na_freq ----------
#> Package Function.used Time
#> 1 massdataset mutate_variable_na_freq() 2022-01-18 09:11:47
#> 2 massdataset mutate_variable_na_freq() 2022-01-18 09:11:47
#> 3 massdataset mutate_variable_na_freq() 2022-01-18 09:11:47
#> filter ----------
#> Package Function.used Time
#> 1 massdataset filter() 2022-01-18 09:11:47
#> 2 massdataset filter() 2022-03-07 17:27:46
#> 3 massdataset filter() 2022-03-07 17:27:46
#> impute_mv ----------
#> Package Function.used Time
#> 1 masscleaner impute_mv() 2022-01-18 09:38:06
#> normalize_data ----------
#> Package Function.used Time
#> 1 masscleaner normalize_data() 2022-01-18 09:50:47
#> integrate_data ----------
#> Package Function.used Time
#> 1 masscleaner integrate_data() 2022-01-18 09:50:47
#> update_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset update_mass_dataset() 2022-01-19 21:53:37
#> mutate_ms2 ----------
#> Package Function.used Time
#> 1 massdataset mutate_ms2() 2022-01-19 21:54:06
#> annotate_metabolites_mass_dataset ----------
#> Package Function.used Time
#> 1 metid annotate_metabolites_mass_dataset() 2022-02-22 21:50:29
#> 2 metid annotate_metabolites_mass_dataset() 2022-02-22 22:08:10
#> 3 metid annotate_metabolites_mass_dataset() 2022-02-22 22:26:33
#> merge_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset merge_mass_dataset 2022-03-07 17:27:46Trace processing information of object
Then we can use the report_parameters() function to trace processing information of object.
All the analysis results will be placed in a folder named as statistical_analysis.
dir.create(path = "statistical_analysis", showWarnings = FALSE)
report_parameters(object = object, path = "statistical_analysis/")
#> processing file: tidymass_parameters.template.Rmd
#> output file: tidymass_parameters.template.knit.md
#> /Applications/RStudio.app/Contents/MacOS/pandoc/pandoc +RTS -K512m -RTS tidymass_parameters.template.knit.md --to html4 --from markdown+autolink_bare_uris+tex_math_single_backslash --output tidymass_parameters.template.html --lua-filter /Library/Frameworks/R.framework/Versions/library/rmarkdown/rmarkdown/lua/pagebreak.lua --lua-filter /Library/Frameworks/R.framework/Versions/library/rmarkdown/rmarkdown/lua/latex-div.lua --self-contained --variable bs3=TRUE --standalone --section-divs --template /Library/Frameworks/R.framework/Versions/library/rmarkdown/rmd/h/default.html --no-highlight --variable highlightjs=1 --variable theme=bootstrap --include-in-header /var/folders/m8/z8rq9r453dn9rk4zx4cw5_5h0000gn/T//RtmpcRItde/rmarkdown-stre9ae21d3ad9b.html --mathjax --variable 'mathjax-url:https://mathjax.rstudio.com/latest/MathJax.js?config=TeX-AMS-MML_HTMLorMML'
#>
#> Output created: tidymass_parameters.template.html
#> Done.
#> A html format file named as parameter_report.html will be generated.
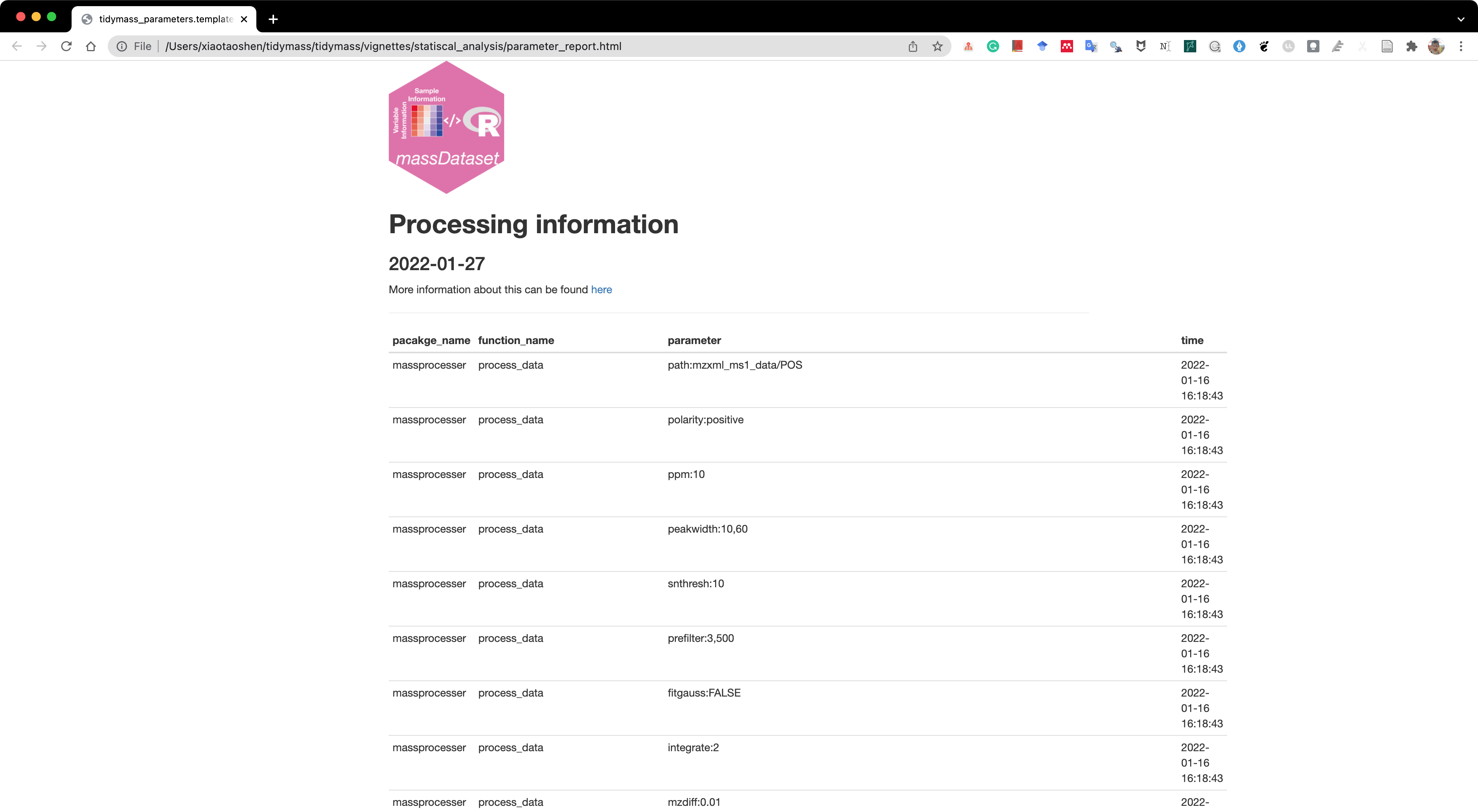
Remove redundant metabolites
Remove the redundant annotated metabolites bases on Level and score.
Differential expression metabolites
Calculate the fold changes.
control_sample_id =
object %>%
activate_mass_dataset(what = "sample_info") %>%
filter(group == "Control") %>%
pull(sample_id)
case_sample_id =
object %>%
activate_mass_dataset(what = "sample_info") %>%
filter(group == "Case") %>%
pull(sample_id)
object <-
mutate_fc(object = object,
control_sample_id = control_sample_id,
case_sample_id = case_sample_id,
mean_median = "mean")
#> 110 control samples.
#> 110 case samples.
#> Calculate p values.
object <-
mutate_p_value(
object = object,
control_sample_id = control_sample_id,
case_sample_id = case_sample_id,
method = "t.test",
p_adjust_methods = "BH"
)
#> 110 control samples.
#> 110 case samples.
#> Volcano plot.
volcano_plot(object = object,
add_text = TRUE,
text_from = "Compound.name",
point_size_scale = "p_value") +
scale_size_continuous(range = c(0.5, 5))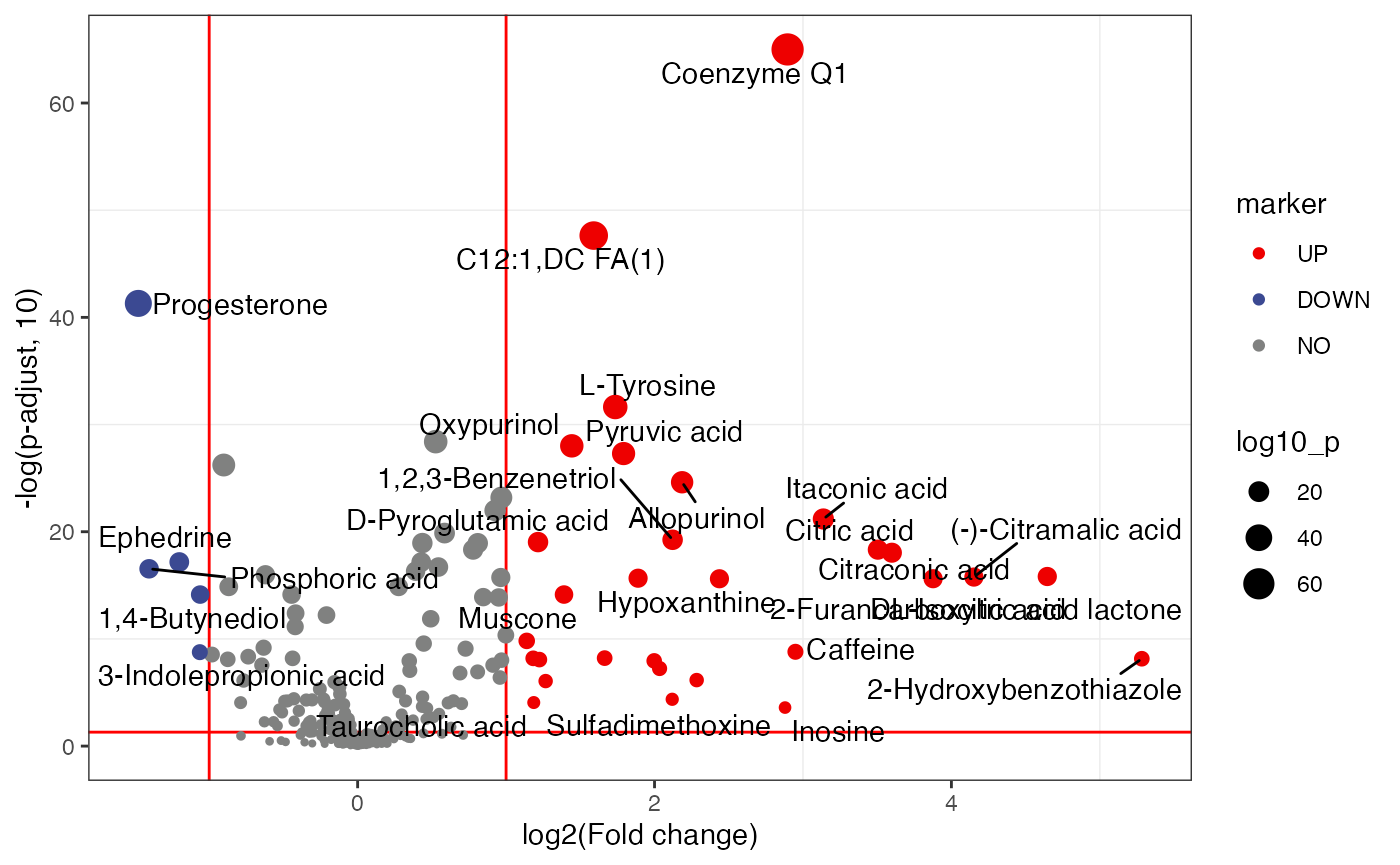
Output result
Output the differential expression metabolites.
differential_metabolites <-
extract_variable_info(object = object) %>%
filter(fc > 2 | fc < 0.5) %>%
filter(p_value_adjust < 0.05)
readr::write_csv(differential_metabolites,
file = "statistical_analysis/differential_metabolites.csv")Save result for subsequent analysis.
object_final <- object
save(object_final, file = "statistical_analysis/object_final")Session information
sessionInfo()
#> R version 4.1.2 (2021-11-01)
#> Platform: x86_64-apple-darwin17.0 (64-bit)
#> Running under: macOS Big Sur 10.16
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRlapack.dylib
#>
#> locale:
#> [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#>
#> attached base packages:
#> [1] stats4 stats graphics grDevices utils datasets methods
#> [8] base
#>
#> other attached packages:
#> [1] knitr_1.37 forcats_0.5.1.9000 stringr_1.4.0
#> [4] purrr_0.3.4 readr_2.1.2 tidyr_1.2.0
#> [7] tibble_3.1.6 tidyverse_1.3.1 tinytools_0.9.1
#> [10] dplyr_1.0.8 metid_1.2.4 metpath_0.99.2
#> [13] massstat_0.99.12 ggfortify_0.4.14 massqc_0.99.7
#> [16] masscleaner_0.99.7 xcms_3.16.1 MSnbase_2.20.4
#> [19] ProtGenerics_1.26.0 S4Vectors_0.32.3 mzR_2.28.0
#> [22] Rcpp_1.0.8 Biobase_2.54.0 BiocGenerics_0.40.0
#> [25] BiocParallel_1.28.3 massprocesser_0.99.3 ggplot2_3.3.5
#> [28] magrittr_2.0.2 masstools_0.99.4 massdataset_0.99.14
#> [31] tidymass_0.99.5
#>
#> loaded via a namespace (and not attached):
#> [1] ragg_1.2.1 bit64_4.0.5
#> [3] missForest_1.4 DelayedArray_0.20.0
#> [5] data.table_1.14.2 rpart_4.1.16
#> [7] KEGGREST_1.34.0 RCurl_1.98-1.5
#> [9] doParallel_1.0.17 generics_0.1.2
#> [11] snow_0.4-4 leaflet_2.1.0
#> [13] preprocessCore_1.56.0 mixOmics_6.18.1
#> [15] RANN_2.6.1 proxy_0.4-26
#> [17] future_1.23.0 bit_4.0.4
#> [19] tzdb_0.2.0 xml2_1.3.3
#> [21] lubridate_1.8.0 ggsci_2.9
#> [23] SummarizedExperiment_1.24.0 assertthat_0.2.1
#> [25] viridis_0.6.2 xfun_0.29
#> [27] hms_1.1.1 jquerylib_0.1.4
#> [29] evaluate_0.15 DEoptimR_1.0-10
#> [31] fansi_1.0.2 dbplyr_2.1.1
#> [33] readxl_1.3.1 igraph_1.2.11
#> [35] DBI_1.1.2 htmlwidgets_1.5.4
#> [37] MsFeatures_1.3.0 rARPACK_0.11-0
#> [39] ellipsis_0.3.2 RSpectra_0.16-0
#> [41] crosstalk_1.2.0 backports_1.4.1
#> [43] ggcorrplot_0.1.3 MatrixGenerics_1.6.0
#> [45] vctrs_0.3.8 remotes_2.4.2
#> [47] cachem_1.0.6 withr_2.4.3
#> [49] ggforce_0.3.3 itertools_0.1-3
#> [51] robustbase_0.93-9 vroom_1.5.7
#> [53] checkmate_2.0.0 cluster_2.1.2
#> [55] lazyeval_0.2.2 crayon_1.5.0
#> [57] ellipse_0.4.2 labeling_0.4.2
#> [59] pkgconfig_2.0.3 tweenr_1.0.2
#> [61] GenomeInfoDb_1.30.0 nnet_7.3-17
#> [63] rlang_1.0.1 globals_0.14.0
#> [65] lifecycle_1.0.1 affyio_1.64.0
#> [67] extrafontdb_1.0 fastDummies_1.6.3
#> [69] MassSpecWavelet_1.60.0 modelr_0.1.8
#> [71] cellranger_1.1.0 randomForest_4.7-1
#> [73] rprojroot_2.0.2 polyclip_1.10-0
#> [75] matrixStats_0.61.0 Matrix_1.4-0
#> [77] reprex_2.0.1 base64enc_0.1-3
#> [79] GlobalOptions_0.1.2 png_0.1-7
#> [81] viridisLite_0.4.0 rjson_0.2.21
#> [83] clisymbols_1.2.0 bitops_1.0-7
#> [85] pander_0.6.4 Biostrings_2.62.0
#> [87] shape_1.4.6 parallelly_1.30.0
#> [89] robust_0.7-0 jpeg_0.1-9
#> [91] gridGraphics_0.5-1 scales_1.1.1
#> [93] memoise_2.0.1 plyr_1.8.6
#> [95] zlibbioc_1.40.0 compiler_4.1.2
#> [97] RColorBrewer_1.1-2 pcaMethods_1.86.0
#> [99] clue_0.3-60 rrcov_1.6-2
#> [101] cli_3.2.0 affy_1.72.0
#> [103] XVector_0.34.0 listenv_0.8.0
#> [105] patchwork_1.1.1 pbapply_1.5-0
#> [107] htmlTable_2.4.0 Formula_1.2-4
#> [109] MASS_7.3-55 tidyselect_1.1.1
#> [111] vsn_3.62.0 stringi_1.7.6
#> [113] textshaping_0.3.6 highr_0.9
#> [115] yaml_2.3.4 latticeExtra_0.6-29
#> [117] MALDIquant_1.21 ggrepel_0.9.1
#> [119] grid_4.1.2 sass_0.4.0
#> [121] tools_4.1.2 parallel_4.1.2
#> [123] circlize_0.4.14 rstudioapi_0.13
#> [125] MsCoreUtils_1.6.0 foreach_1.5.2
#> [127] foreign_0.8-82 gridExtra_2.3
#> [129] farver_2.1.0 mzID_1.32.0
#> [131] ggraph_2.0.5 rvcheck_0.2.1
#> [133] digest_0.6.29 BiocManager_1.30.16
#> [135] GenomicRanges_1.46.1 broom_0.7.12
#> [137] ncdf4_1.19 httr_1.4.2
#> [139] ComplexHeatmap_2.10.0 colorspace_2.0-2
#> [141] rvest_1.0.2 XML_3.99-0.8
#> [143] fs_1.5.2 IRanges_2.28.0
#> [145] splines_4.1.2 yulab.utils_0.0.4
#> [147] graphlayouts_0.8.0 pkgdown_2.0.2
#> [149] ggplotify_0.1.0 plotly_4.10.0
#> [151] systemfonts_1.0.3 fit.models_0.64
#> [153] jsonlite_1.7.3 tidygraph_1.2.0
#> [155] corpcor_1.6.10 R6_2.5.1
#> [157] Hmisc_4.6-0 pillar_1.7.0
#> [159] htmltools_0.5.2 glue_1.6.1
#> [161] fastmap_1.1.0 class_7.3-20
#> [163] codetools_0.2-18 pcaPP_1.9-74
#> [165] mvtnorm_1.1-3 furrr_0.2.3
#> [167] utf8_1.2.2 lattice_0.20-45
#> [169] bslib_0.3.1 zip_2.2.0
#> [171] openxlsx_4.2.5 Rttf2pt1_1.3.9
#> [173] survival_3.2-13 limma_3.50.0
#> [175] rmarkdown_2.11 desc_1.4.0
#> [177] munsell_0.5.0 e1071_1.7-9
#> [179] GetoptLong_1.0.5 GenomeInfoDbData_1.2.7
#> [181] iterators_1.0.14 impute_1.68.0
#> [183] haven_2.4.3 reshape2_1.4.4
#> [185] gtable_0.3.0 extrafont_0.17